Introduction
This post will show you how we improved the performance of the car classified listing at Autocosmos.com, working with Miguel Ángel Saez and Matías Quaranta. The objective is to show the solution from an architectural point of view, so it may help others with a similar problem.
Autocosmos.com is an auto shopping and information website that serves Hispanic America, and runs entirely on Microsoft Azure. You can learn about the migration from on-premises to the cloud at this Microsoft Customer Story.
Scenario
As most traditional software solutions, Autocosmos uses a relational database to store most of its data. As it is hosted in Azure, the RDBMS in use is the Azure SQL Database service.
The classified car listing, one of the fundamental parts of the site, consists of a list of filters, with the amount of results in each filter, and a paged results list, that looks like the image below:
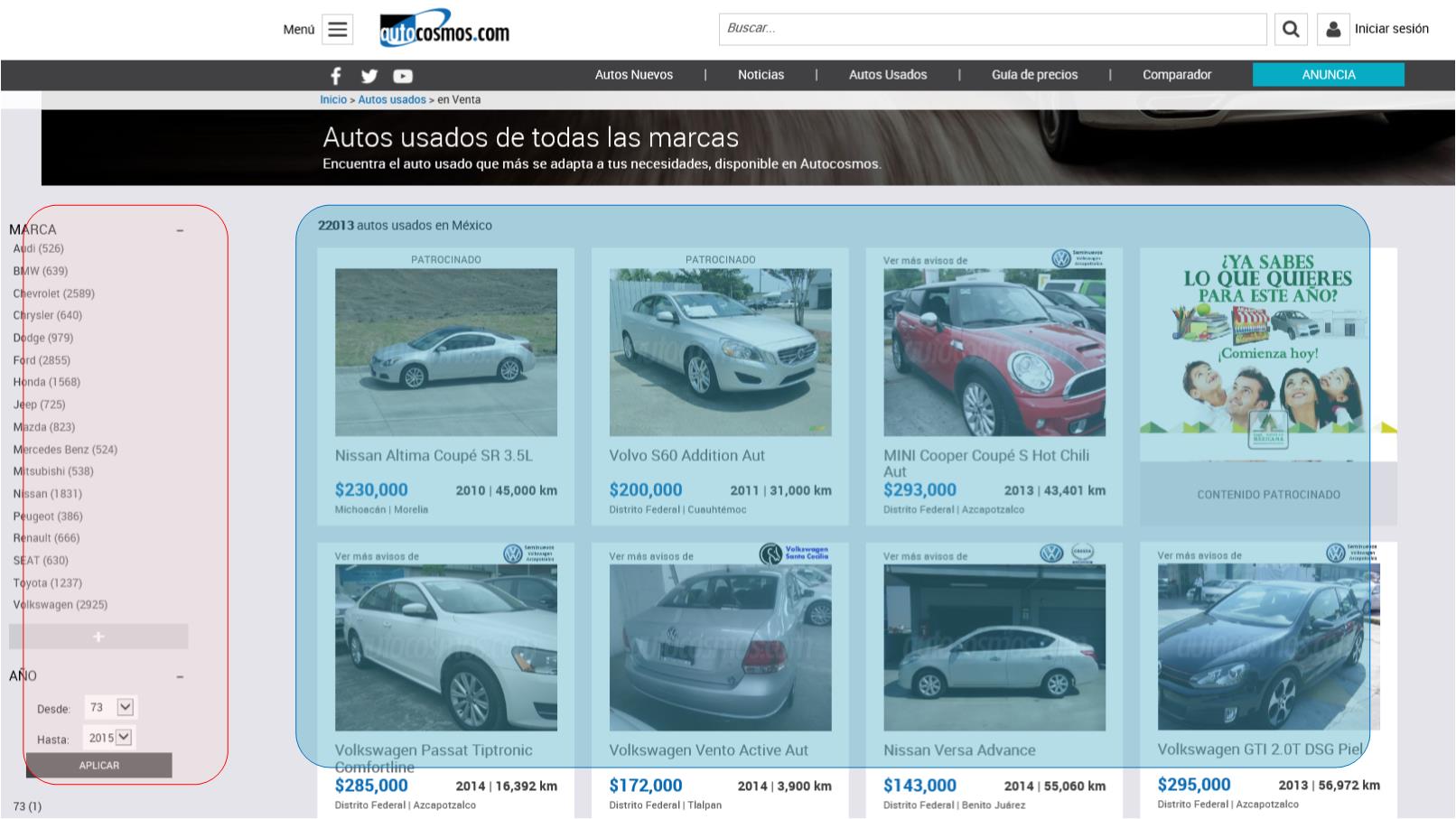
Site layout: filters on the left (red) and the paged results on the right (blue).
Analyzing performance issues
To analyze the performance of the site, and get reliable metrics, we used New Relic. This allowed us to detect the specific performance points we should tackle, and gave us the time and processing power consumed by these processes. Without having the actual values it’s impossible to determine if a change is improving the system or not.
The first thing we realized was that the process that was consuming most of the time and processing was the calculation of the filters and their statistics values.
The metrics before starting this process were the ones below:

Metrics before starting the process (whole week response time and throughput)
The average response time was around 7 seconds, with spikes of over 20 seconds!! Clearly, this was unacceptable! And the throughput was an average of 152 rpm (requests per minute).
As you may have realized by looking at the top chart, that area in violet was taking most of the time, and that area represents the database access. So, we had identified the problem, we had to aim at the database: doing the calculations to get the amount of results with each of the available filters puts a heavy load on the database.
The long road to performance
Step one: SQL performance
We had to start somewhere, and given the problem was clearly in the database access, we started looking at the database structure (schema, indexes, fields, queries) to find which were the spots where we could make an improvement, without modifying the process itself, just optimizing database performance.
The job was to identify missing indexes, and re-write queries by analyzing the performance in the execution plans.
This brought us an increase in performance (response time reduction) of around 30%, and the spikes were reduced to around 10 seconds (50% less), as shown in the chart below.

Response time improvement after the database optimization (the full line shows the week after the optimization, dashed line is the week before).
Step two: Azure Redis
There is a point where it is no longer useful to keep trying to optimize the database performance, the effort becomes too large and the benefits are too small. At that point we had to start thinking outside of the box, and come with an alternative path: implementing a caching strategy.
In Azure, a website or cloud service, can scale horizontally to adjust to a higher demand, creating new instances. Each instance has its own, independent, RAM memory. Implementing an in-memory caching strategy would create cached objects in each of the instances independently, and they can’t be shared across the rest of them. And also, in small instances, the amount of memory is limited.
So, the way to go is to implement two levels of cache. The fist one, a local, in-memory cache, in each instance, with small objects, that are not expensive to build, but have a great performance. And a higher second level with more complex and expensive to build objects, that need to be shared across all instances. This second level needs a distributed cache.
Azure Redis is a distributed cache service available in the Microsoft Azure platform. This service allows us to create objects and share them across all our instances and applications. This way, every expensive object created by an instance is immediately available to all other instances needing this same information.
Another important point to be taken into account when dealing with caching is the expiration time for each object. There are objects that can have a long life span, because they are not modified frequently. Other objects are more volatile, and can’t be cached too long. We always need to find the balance between performance and data consistency, something that depends on each business.
In our case, we used it to cache the search results, and their facets and filters. This allowed us to improve the page performance, getting to an average response time of around 2.5 seconds, with peaks at 4 seconds.

Performance improvement after we implemented a distributed Redis cache.
Step three: Azure Search + Azure Redis
Despite the implementation of the distributed cache using Azure Redis, the search engine was still working on Azure SQL Database, which meant that building the cache objects was still taking too long. And, due to the high cardinality of the user searches (due to the large amount of filters the site has), having a search issued without having an associated pre-built object in cache was a frequent case.
The solution was to change the search engine completely: we implemented Azure Search.
Azure Search allows us to create indexes, to store documents, and use the Elastic Search engine to search over those documents, using all the filters we wanted, at amazing speeds, no matter the amount of documents in the results or the filters set.
Also, it calculates the facets (remember that list of filters with the number of results per filter from the first image? well, that). So, we get the benefit of having all the filtering and faceting done at the same time, something that in SQL needed lots of queries.
Azure Search, as every Azure service, has some limitations. In this case we were worried about the QPS limit (queries per second). So, to help with that, we implemented a cache-aside pattern with Azure Redis, where the store is actually Azure Search.

Cache-aside pattern
This way, we managed to reduce the QPS to the Azure Search service, and reduced the response time for the same search.
Now, on the down side, we now need to keep the search index up to date and synced with the SQL Database. Depending on how you store your data, this may be as easy as setting a sync between SQL Database and Azure Search, or having to build a custom process to keep them synced. At the time of implementing this solution, the sync service was not available, so we opted for a combination of Azure Storage queues and a worker role to update the index.
The final results
After going through all the implementation process, and comparing with the original state, we achieved a reduction of around 90% in the response time, and also, we doubled the throughput!

Final results: 90% less response time + 100% more throughput
Additionally, we made a cost reduction. You may be thinking that given the price of the Azure Search service (starts at USD 250) that may not be true. But you must consider that, with the new SQL Database tiers, we would have needed to use at least a Premium P1 (which costs USD 465) for two of our databases. So the costs were reduced, quite a lot.
Conclusions
From an architectural point of view, implementing the search service as an independent service (from the other data repositories) allowed us to improve the performance of the site, and it also helped us reduce the costs, and improve the throughput.
This also opens the doors to other applications to use the search engine, in a decoupled way, directly generating more business opportunities for the team.
I hope this can help other people with similar problems, or at least inspire you to get to the solution, and helps show the potential of Azure Search and Azure Redis services.

Pingback: A step by step guide for using Azure search for your eCommerce store | Tech Vedika Blog
Pingback: A Step-by-Step Guide for Using Azure Search For Your eCommerce Store – Tech Vedika
Hello, I know this is an oooold article and you probably forgot most of it but it´s worth a try at least 🙂
I am trying to handle a similar problem, our case is also that we need to take some load off from Azure Search and I have been thinking about some kind of cache above the search engine. This article was interesting but I would love to better understand the details of what is actually stored in Redis. You mention facets, is that what you store in Redis ?
LikeLike